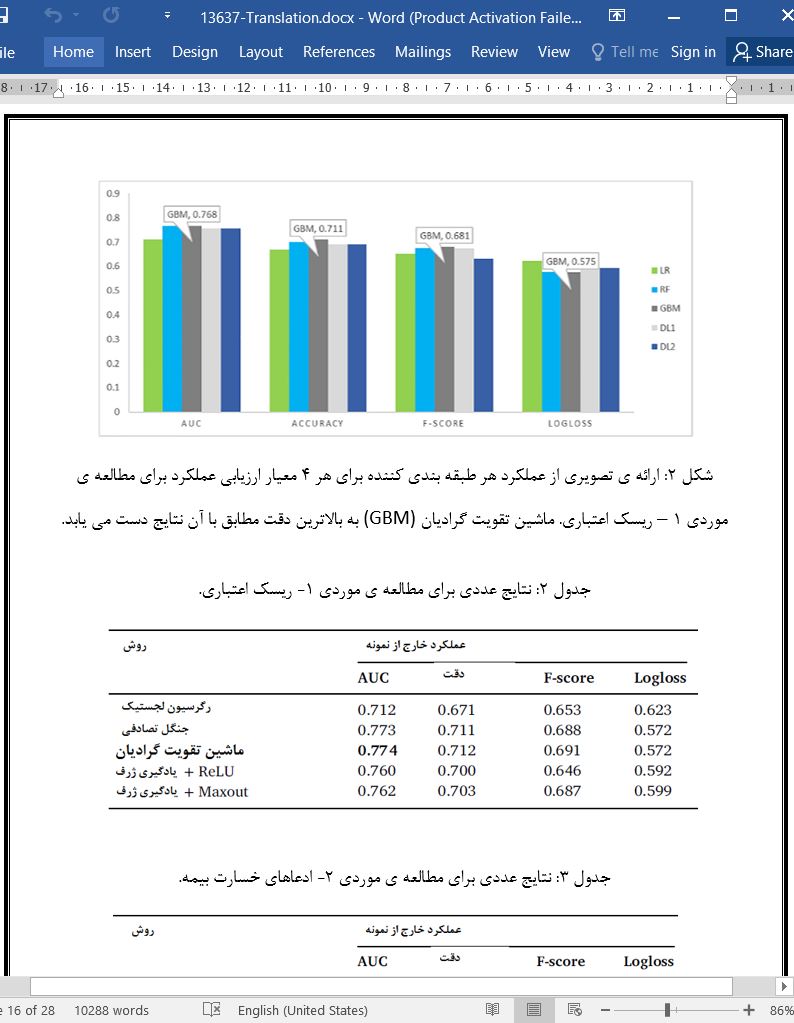
.svg)
.svg)

.svg)

ترجمه مقاله یادگیری عمیق در تجزیه و تحلیل کسب و کار - نشریه الزویر
عنوان فارسی
یادگیری عمیق در تجزیه و تحلیل کسب و کار: برخورد انتظارات و واقعیت
عنوان انگلیسی
Deep learning in business analytics: A clash of expectations and reality
صفحات مقاله فارسی
28
صفحات مقاله انگلیسی
9
سال انتشار
2023
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
الزویر - Elsevier
فرمت مقاله انگلیسی
PDF
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
مقالات پژوهشی (تحقیقاتی)
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
شناسه ISSN مجله
2667-0968
کد محصول
13637
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
ترجمه شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
تایپ شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مدیریت - مهندسی کامپیوتر - مدیریت کسب و کار - مدیریت فناوری اطلاعات - هوش مصنوعی - علوم داده
مجله
International Journal of Information Management Data Insights
کلمات کلیدی
یادگیری ژرف - یادگیری ماشین - واکاوش کسب و کار - هوش مصنوعی - تصمیم گیری داده محور - تحول دیجیتال - استراتژی دیجیتال
کلمات کلیدی انگلیسی
Deep Learning - Machine learning - Business analytics - Artificial intelligence - Data-driven decision making - Digital transformation - Digital strategy
doi یا شناسه دیجیتال
https://doi.org/10.1016/j.jjimei.2022.100146
با خرید این کالا; ترجمه فارسی مقاله، مقاله انگلیسی، پاورپوینت و ترجمه خلاصه قابل دانلود خواهد بود. بلافاصله پس از خرید، دکمه دانلود ظاهر شده و محصول به ایمیل شما نیز ارسال خواهد گردید.
۰.۰
(هنوز امتیازی ثبت نشده است)