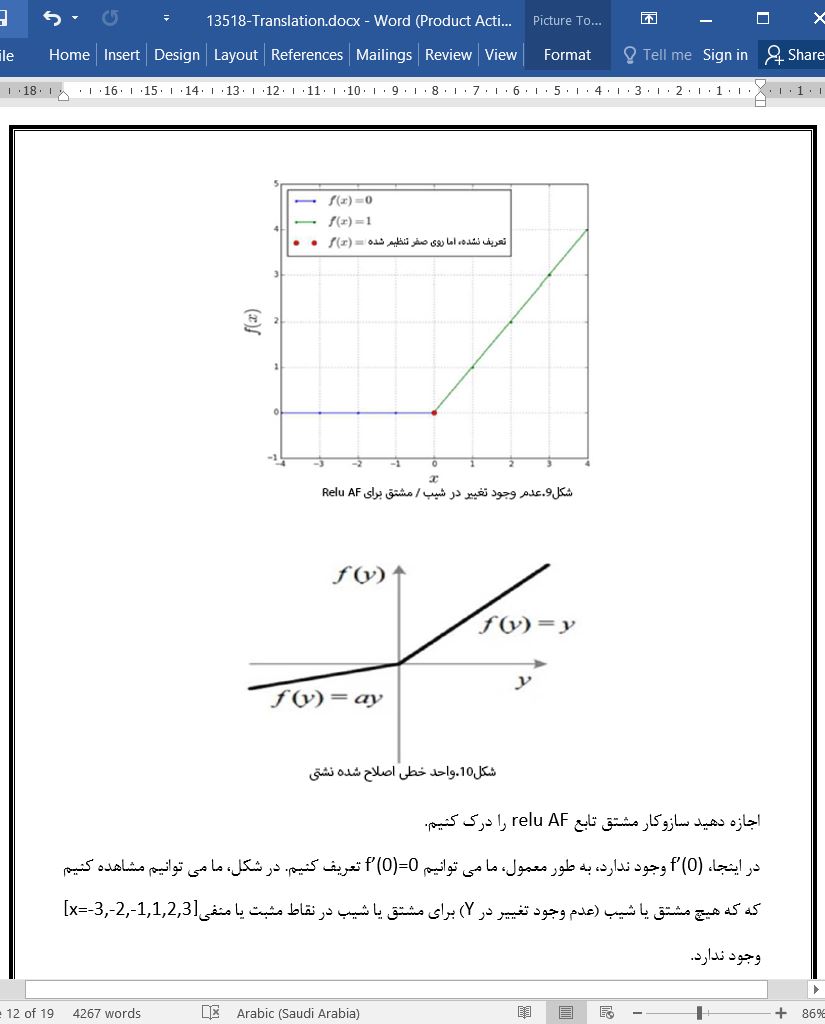
.svg)
.svg)

.svg)

ترجمه مقاله مطالعات تطبیقی تکنیک های یادگیری ماشین و کاربردهای اخیر آن - نشریه IEEE

عنوان فارسی
مقاله مروری: مطالعات تطبیقی تکنیک های یادگیری ماشین و کاربردهای اخیر آن
عنوان انگلیسی
Survey Paper: Comparative Study of Machine Learning Techniques and its Recent Applications
صفحات مقاله فارسی
19
صفحات مقاله انگلیسی
6
سال انتشار
2022
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
آی تریپل ای - IEEE
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
مقاله مروری (Review Article)
نوع ارائه مقاله
کنفرانس
کد محصول
13518
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
تایپ شده است
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
دارد ✓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر - هوش مصنوعی - مهندسی نرم افزار - مهندسی الگوریتم ها و محاسبات
کنفرانس
International Conference on Innovative Practices in Technology and Management
کلمات کلیدی
کاربردهای الگوریتم های یادگیری ماشین - KNN (الگوریتم k-نزدیک ترین همسایگی) - رگرسیون خطی - یادگیری عمیق - SVM (ماشین بردار پشتیبان) - RF (الگوریتم جنگل تصادفی) - توابع فعالسازی
کلمات کلیدی انگلیسی
Applications of Machine Learning Algorithms - KNN - Linear Regression - Deep Learning - SVM - RF - Activation functions
doi یا شناسه دیجیتال
https://doi.org/10.1109/ICIPTM54933.2022.9754206
با خرید این کالا; ترجمه فارسی مقاله، مقاله انگلیسی، پاورپوینت و ترجمه خلاصه قابل دانلود خواهد بود. بلافاصله پس از خرید، دکمه دانلود ظاهر شده و محصول به ایمیل شما نیز ارسال خواهد گردید.
۰.۰
(هنوز امتیازی ثبت نشده است)