.svg)
.svg)

.svg)

ترجمه مقاله مطالعه تجربی درباره برخی تکنیک های پیش بینی خطای نرم افزار به منظور تعداد پیش بینی خطاها - نشریه اشپرینگر

عنوان فارسی
مطالعه تجربی درباره برخی تکنیک های پیش بینی خطای نرم افزار به منظور تعداد پیش بینی خطاها
عنوان انگلیسی
An empirical study of some software fault prediction techniques for the number of faults prediction
صفحات مقاله فارسی
36
صفحات مقاله انگلیسی
18
سال انتشار
2016
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
اشپرینگر - Springer
فرمت مقاله انگلیسی
PDF
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
3.864 در سال 2020
شاخص H_index مجله
81 در سال 2021
شاخص SJR مجله
0.626 در سال 2020
شناسه ISSN مجله
1432-7643
شاخص Q یا Quartile (چارک)
Q2 در سال 2020
کد محصول
12294
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت انگلیسی درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
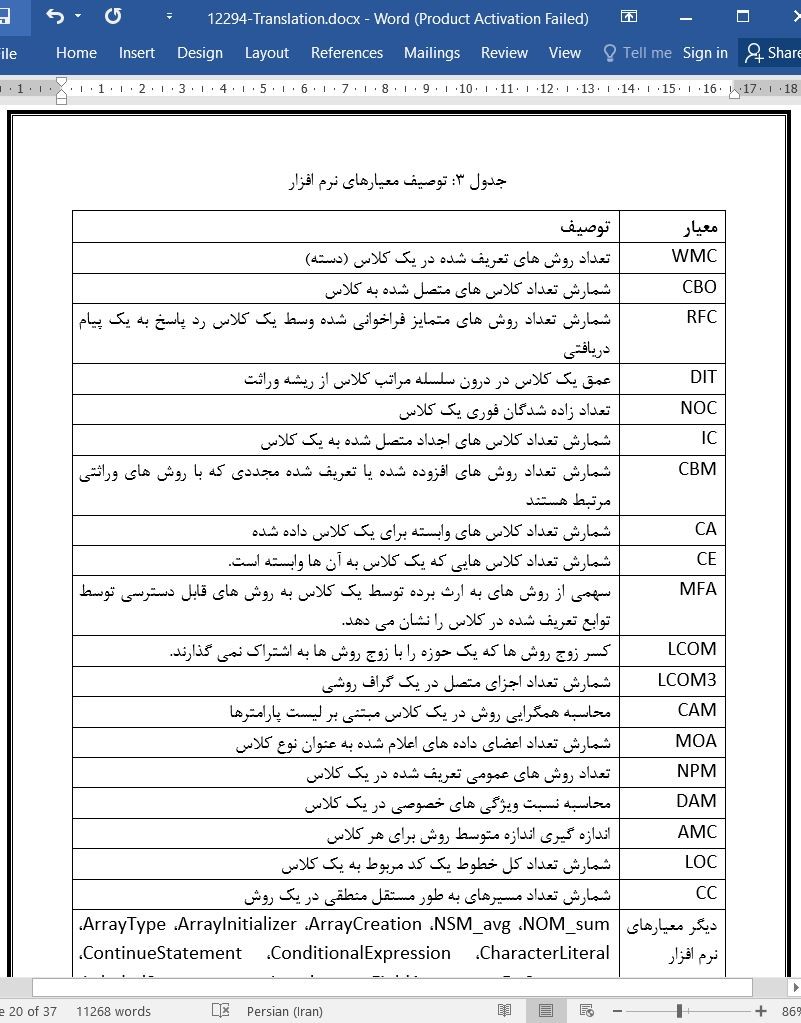
به صورت عکس، درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته های مرتبط با این مقاله
مهندسی کامپیوتر
گرایش های مرتبط با این مقاله
مهندسی نرم افزار، طراحی و تولید نرم افزار
دانشگاه
گروه علوم و مهندسی کامپیوتر، موسسه فناوری هند روکی، هند
کلمات کلیدی
پیش بینی خطای نرم افزار، رگرسیون پوآسون بدون تورم، برنامه نویسی ژنتیک، پرسپترون چند لایه، تست Kruskal–Wallis، تست مقایسه چندگانه Dunn
کلمات کلیدی انگلیسی
Software fault prediction - Zero-inflated Poisson regression - Genetic programming - Multilayer perceptron - Kruskal–Wallis test - Dunn’s multiple comparison test
doi یا شناسه دیجیتال
https://doi.org/10.1007/s00500-016-2284-x
۰.۰
(هنوز امتیازی ثبت نشده است)