Abstract
Analogy-based effort estimation (ABE) is one of the efficient methods for software effort estimation because of its outstanding performance and capability of handling noisy datasets. Conventional ABE models usually use the same number of analogies for all projects in the datasets in order to make good estimates. The authors' claim is that using same number of analogies may produce overall best performance for the whole dataset but not necessarily best performance for each individual project. Therefore there is a need to better understand the dataset characteristics in order to discover the optimum set of analogies for each project rather than using a static k nearest projects. The authors propose a new technique based on bisecting k- medoids clustering algorithm to come up with the best set of analogies for each individual project before making the prediction. With bisecting k- medoids it is possible to better understand the dataset characteristic, and automatically find best set of analogies for each test project. Performance figures of the proposed estimation method are promising and better than those of other regular ABE models.
1 Introduction
Analogy-based effort estimation (ABE) is simplified a process of finding nearest analogies based on notion of retrieval by similarity [1–4]. It was remarked that the predictive performance of ABE is a dataset dependent where each dataset requires different configurations and design decisions [5–8]. Recent publications reported the importance of adjustment mechanism for generating better estimates in ABE than null-adjustment mechanism [1, 9, 10]. However, irrespective of the type of adjustment technique followed, the process of discovering the best set of analogies to be used is still a key challenge.
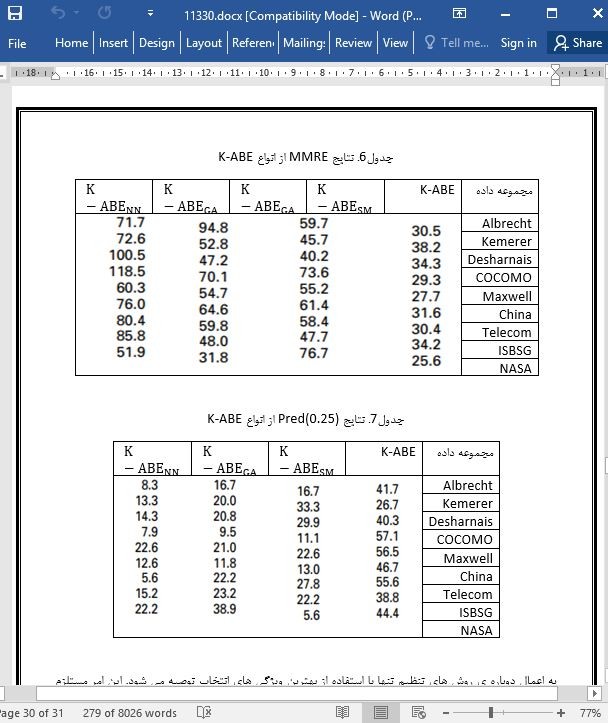
7 Conclusions
In this paper, we presented the problem of discovering the optimum set of analogies to be used by ABE in order to make good software effort estimates. However, it is well recognised that the use of fixed number of analogies for all test projects is not sufficient to obtain better predictive performance. In our paper we defined four research questions to address the traditional problem of tuning ABE methods: (1) understanding the structure of data and (2) finding a technique to automatically discovering the set of analogies to be used for every single project. Therefore we proposed a new technique based on utilising BK clustering algorithm and variance degree. Therefore rather than proposing a fixed k value a priori as the traditional ABE methods do, what k-ABE does is starting with all the training samples in the dataset, learning the dataset to form BK binary tree and excluding the irrelevant analogies on the basis of variance degree and discovering the optimum set of k analogies for each individual project. The proposed technique has the capability to support different size of datasets that have a lot of categorical features. The main aim of utilising BK tree is to improve the predictive performance of ABE via: (1) building itself by discovering the characteristics of a particular dataset on its own and, (2) excluding outlying projects on the basis of variance degree.