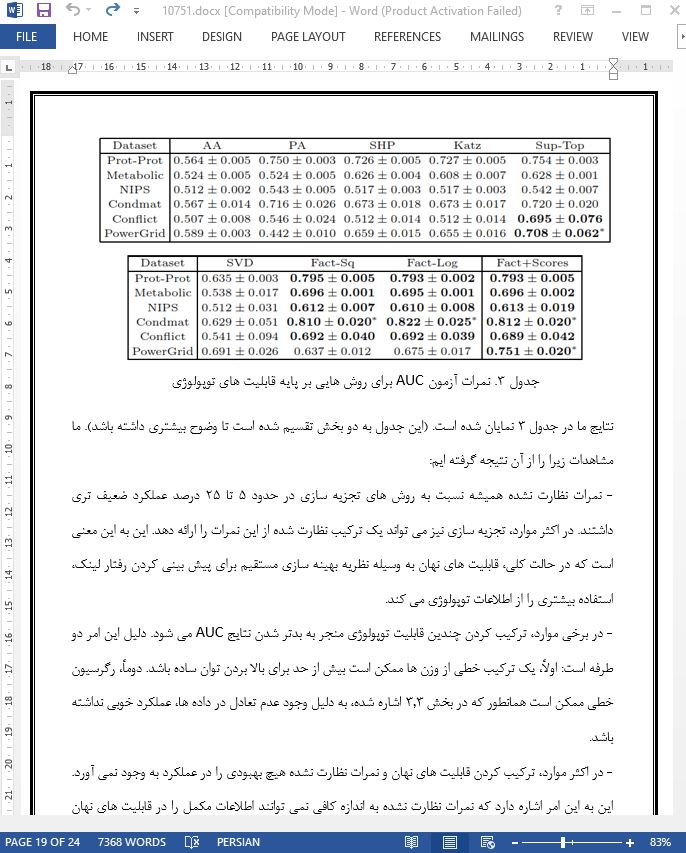
.svg)
.svg)

.svg)

ترجمه مقاله پیش بینی لینک توسط تجزیه ماتریس - نشریه اشپرینگر

عنوان فارسی
پیش بینی لینک توسط تجزیه ماتریس
عنوان انگلیسی
Link Prediction via Matrix Factorization
صفحات مقاله فارسی
24
صفحات مقاله انگلیسی
16
سال انتشار
2011
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
اشپرینگر - Springer
فرمت مقاله انگلیسی
PDF
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
کنفرانس
کد محصول
10751
وضعیت ترجمه منابع داخل متن
درج نشده است ☓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته های مرتبط با این مقاله
مهندسی کامپیوتر و مهندسی فناوری اطلاعات
گرایش های مرتبط با این مقاله
شبکه های کامپیوتری، مهندسی نرم افزار
دانشگاه
دانشگاه کالیفرنیا، سن دیگو لا جولا، کالیفرنیا
کلمات کلیدی
پیش بینی لینک، تجزیه ماتریس، اطلاع کناری، زیان رتبه بندی
کلمات کلیدی انگلیسی
Link prediction - matrix factorization - side information - ranking loss
doi یا شناسه دیجیتال
https://doi.org/10.1007/978-3-642-23783-6_28
۰.۰
(هنوز امتیازی ثبت نشده است)