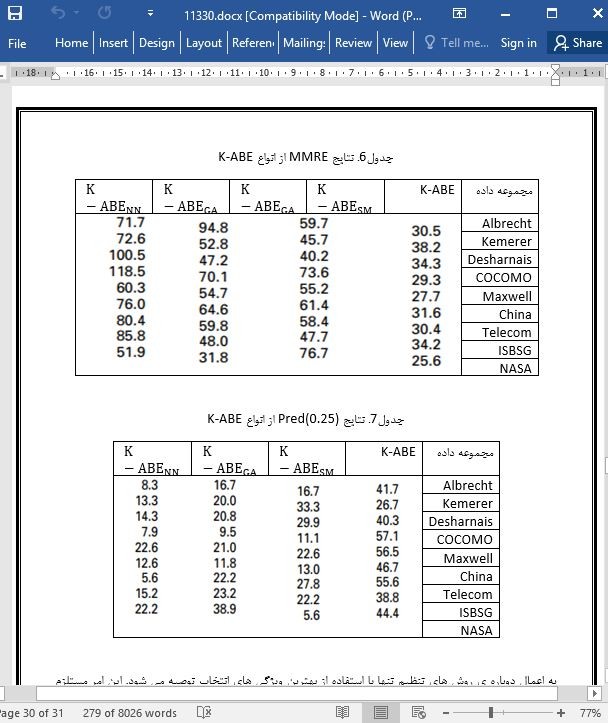
.svg)
.svg)

.svg)

ترجمه مقاله قیاس مبنی بر تخمین تلاش: کشف مجموعه شباهت ها از ویژگی های مجموعه داده - نشریه IEEE

عنوان فارسی
قیاس مبنی بر تخمین تلاش: یک روش جدید برای کشف مجموعه شباهت ها از ویژگی های مجموعه داده
عنوان انگلیسی
Analogy-based effort estimation: a new method to discover set of analogies from dataset characteristics
صفحات مقاله فارسی
31
صفحات مقاله انگلیسی
13
سال انتشار
2015
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
آی تریپل ای - IEEE
فرمت مقاله انگلیسی
PDF
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
2.097 در سال 2019
شاخص H_index مجله
40 در سال 2020
شاخص SJR مجله
0.318 در سال 2019
شناسه ISSN مجله
1751-8806
شاخص Q یا Quartile (چارک)
Q3 در سال 2019
کد محصول
11330
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه نشده است ☓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر، مهندسی نرم افزار، مهندسی الگوریتم ها و محاسبات، طراحی و تولید نرم افزار
مجله
موسسه مهندسی و فناوری نرم افزار - IET Software
دانشگاه
دانشگاه غربی، لندن، کالیفرنیا
doi یا شناسه دیجیتال
https://doi.org/10.1049/iet-sen.2013.0165
۰.۰
(هنوز امتیازی ثبت نشده است)