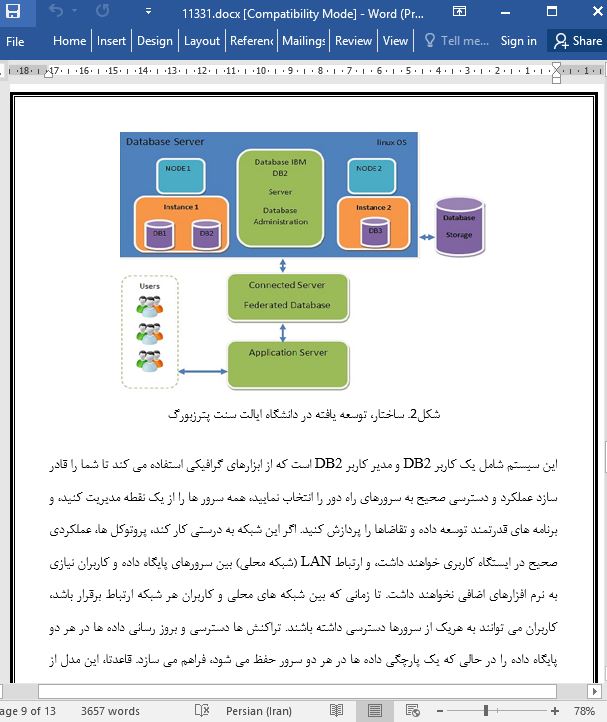
.svg)
.svg)

.svg)

ترجمه مقاله سیستم های ذخیره و پردازش داده ها در فضای ابری بر اساس تکنولوژی یک پارچه سازی - نشریه اشپرینگر

عنوان فارسی
سیستم های ذخیره و پردازش داده ها در فضای ابری بر اساس تکنولوژی یک پارچه سازی
عنوان انگلیسی
Storage Database System in the Cloud Data Processing on the Base of Consolidation Technology
صفحات مقاله فارسی
13
صفحات مقاله انگلیسی
10
سال انتشار
2013
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
اشپرینگر - Springer
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
کنفرانس
کد محصول
11331
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه نشده است ☓
وضعیت ترجمه منابع داخل متن
ترجمه نشده است ☓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته های مرتبط با این مقاله
مهندسی کامپیوتر
گرایش های مرتبط با این مقاله
رایانش ابری، مهندسی نرم افزار
کنفرانس
کنفرانس بین المللی علوم محاسباتی و کاربردهای آن - International Conference on Computational Science and Its Applications
دانشگاه
دانشگاه دولتی سن پترزبورگ، روسیه
کلمات کلیدی
سیستم های پایگاه داده، محاسبات فضای ابری، تکنولوژی یک پارچه سازی، فضای ابری هیبریدی، سیستم های منتشر، فضای ابری متمرکز، پایگاه داده های همبسته،DB2 IBM، DBMS، Vmware، Virtual server، SMP،MPP، پردازش مجازی
کلمات کلیدی انگلیسی
Database system - Cloud computing - Cosolidation technology - Hybrid cloud - Distributed system - Centralized databases - Federated databases - IBM DB2 - DBMS - Vmware - Virtual server - SMP - MPP - Virtual processing
doi یا شناسه دیجیتال
https://doi.org/10.1007/978-3-319-21410-8_24
۰.۰
(هنوز امتیازی ثبت نشده است)