

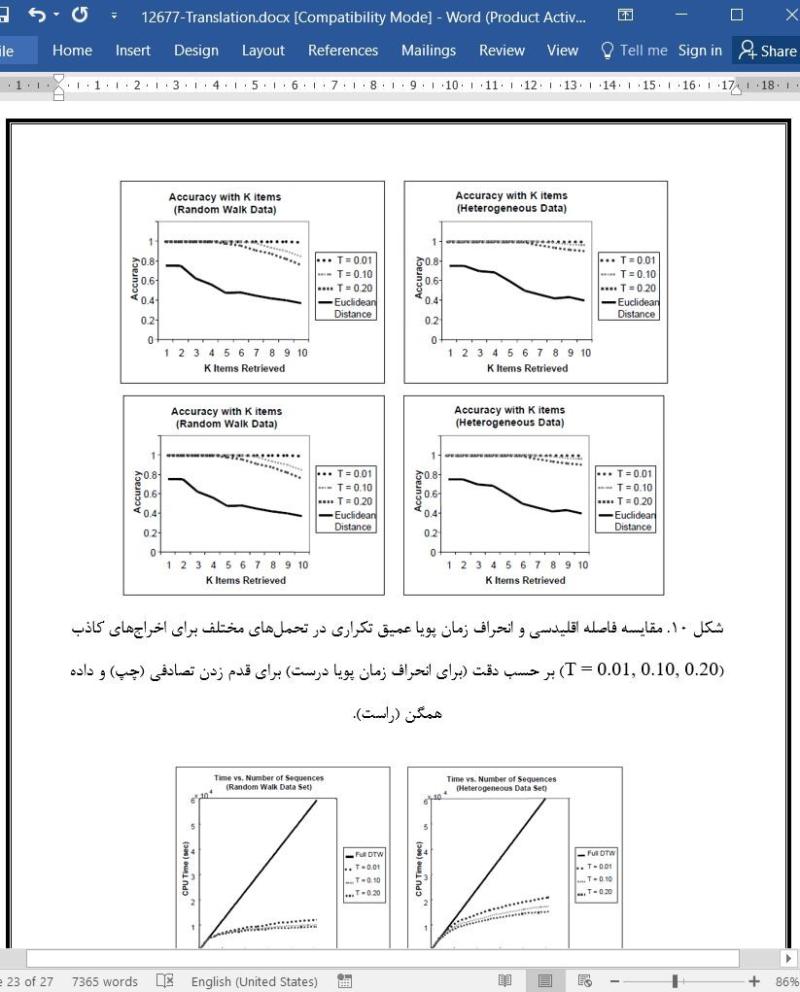
.svg)
.svg)

.svg)

ترجمه مقاله انحراف زمان پویای عمیق تکراری برای سری زمانی







عنوان فارسی
انحراف زمان پویای عمیق تکراری برای سری زمانی
عنوان انگلیسی
Iterative Deepening Dynamic Time Warping for Time Series
صفحات مقاله فارسی
27
صفحات مقاله انگلیسی
18
سال انتشار
2002
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
سایز ترجمه مقاله
14
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
نوع ارائه مقاله
کنفرانس
کد محصول
12677
بیس
نیست ☓
پرسشنامه
ندارد ☓
رفرنس در ترجمه
در داخل متن و انتهای مقاله درج شده است
ضمیمه
ندارد ☓
فرضیه
ندارد ☓
متغیر
ندارد ☓
مدل مفهومی
ندارد ☓
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه نشده است ☓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
doi یا شناسه دیجیتال
https://doi.org/10.1137/1.9781611972726.12
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر - مهندسی اگوریتم ها و محاسبات - مهندسی نرم افزار - علوم داده
کنفرانس
Proceedings of the 2002 SIAM International Conference on Data Mining
۰.۰
(هنوز امتیازی ثبت نشده است)




