

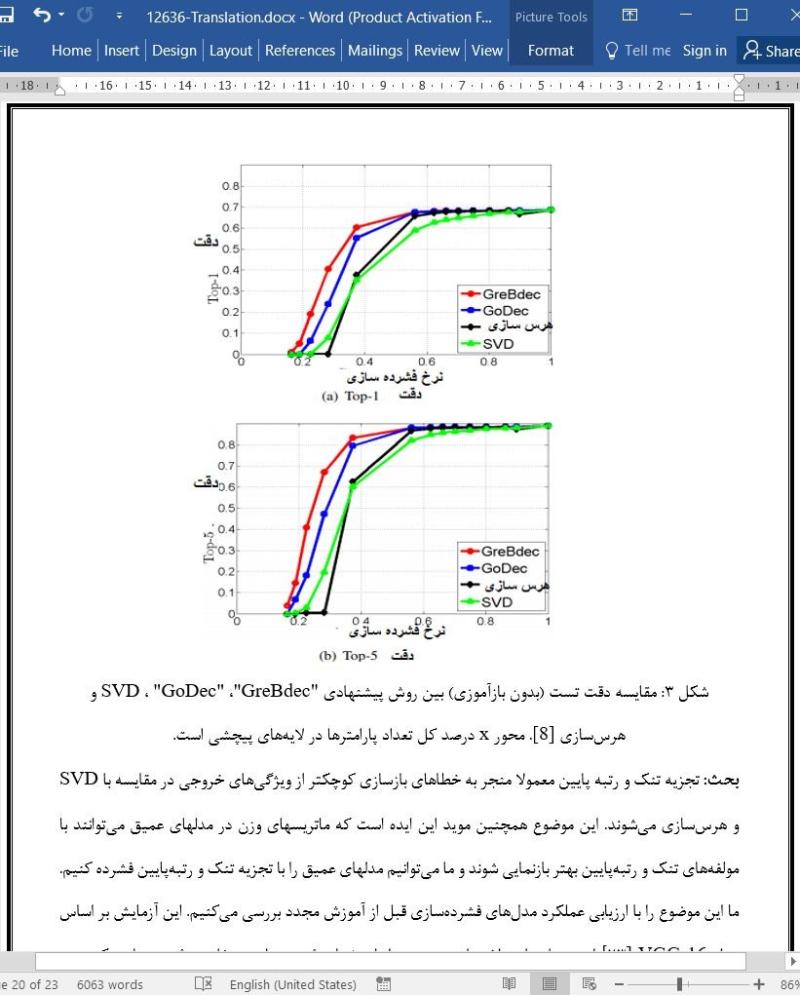
.svg)
.svg)

.svg)

ترجمه مقاله درباره فشرده سازی مدل های عمیق به وسیله رتبه پایین و تجزیه تنک







عنوان فارسی
درباره فشرده سازی مدل های عمیق به وسیله رتبه پایین و تجزیه تنک
عنوان انگلیسی
On Compressing Deep Models by Low Rank and Sparse Decomposition
صفحات مقاله فارسی
22
صفحات مقاله انگلیسی
10
سال انتشار
2017
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
سایز ترجمه مقاله
14
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت مقاله انگلیسی
PDF
فونت ترجمه مقاله
بی نازنین
نشریه
آی تریپل ای - IEEE
نوع ارائه مقاله
کنفرانس
نوع مقاله
ISI
ایمپکت فاکتور(IF) مجله
21.762 در سال 2023
شاخص H_index مجله
531 در سال 2024
شاخص SJR مجله
10.331 در سال 2023
شناسه ISSN مجله
1063-6919
کد محصول
12636
بیس
نیست ☓
پرسشنامه
ندارد ☓
رفرنس در ترجمه
در داخل متن و انتهای مقاله درج شده است
ضمیمه
ندارد ☓
فرضیه
ندارد ☓
متغیر
ندارد ☓
مدل مفهومی
ندارد ☓
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
doi یا شناسه دیجیتال
https://doi.org/10.1109/CVPR.2017.15
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر - هوش مصنوعی - مهندسی الگوریتم ها و محاسبات
کنفرانس
IEEE Conference on Computer Vision and Pattern Recognition
۰.۰
(هنوز امتیازی ثبت نشده است)


