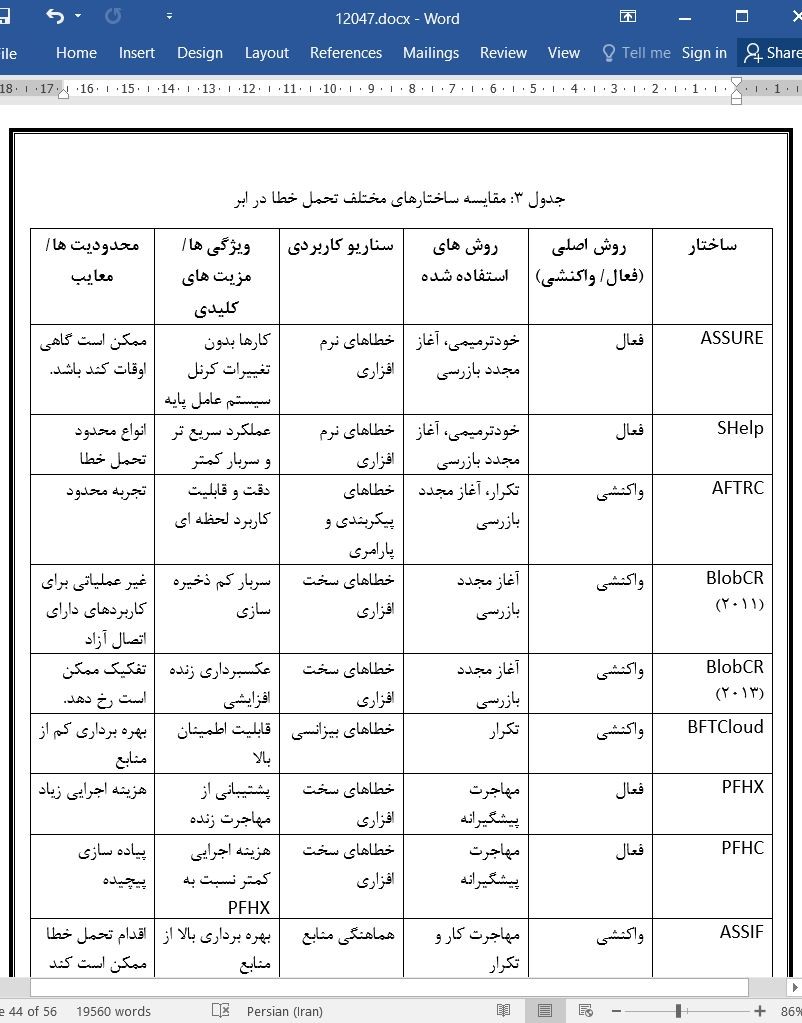
.svg)
.svg)

.svg)

ترجمه مقاله تحمل خطا در محیط رایانش ابری - نشریه الزویر
عنوان فارسی
تحمل خطا در محیط رایانش ابری: یک بررسی سیستماتیک
عنوان انگلیسی
Fault tolerance in cloud computing environment: A systematic survey
صفحات مقاله فارسی
56
صفحات مقاله انگلیسی
17
سال انتشار
2018
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
الزویر - Elsevier
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
مقاله مروری (Review Article)
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
9.962 در سال 2020
شاخص H_index مجله
100 در سال 2021
شاخص SJR مجله
1.432 در سال 2020
شناسه ISSN مجله
0166-3615
شاخص Q یا Quartile (چارک)
Q1 در سال 2020
کد محصول
12047
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر و رایانش ابری
مجله
کامپیوتر در صنعت - Computers in Industry
دانشگاه
گروه علوم و مهندسی کامپیوتر، موسسه مهندسی و فناوری Sant Longowal، هند
کلمات کلیدی
رایانش ابری، خطاها و خرابی ها، تحمل خطا، تحقیق
کلمات کلیدی انگلیسی
Cloud computing - Faults and failures - Fault tolerance - Survey
doi یا شناسه دیجیتال
https://doi.org/10.1016/j.compind.2018.03.027
۰.۰
(هنوز امتیازی ثبت نشده است)