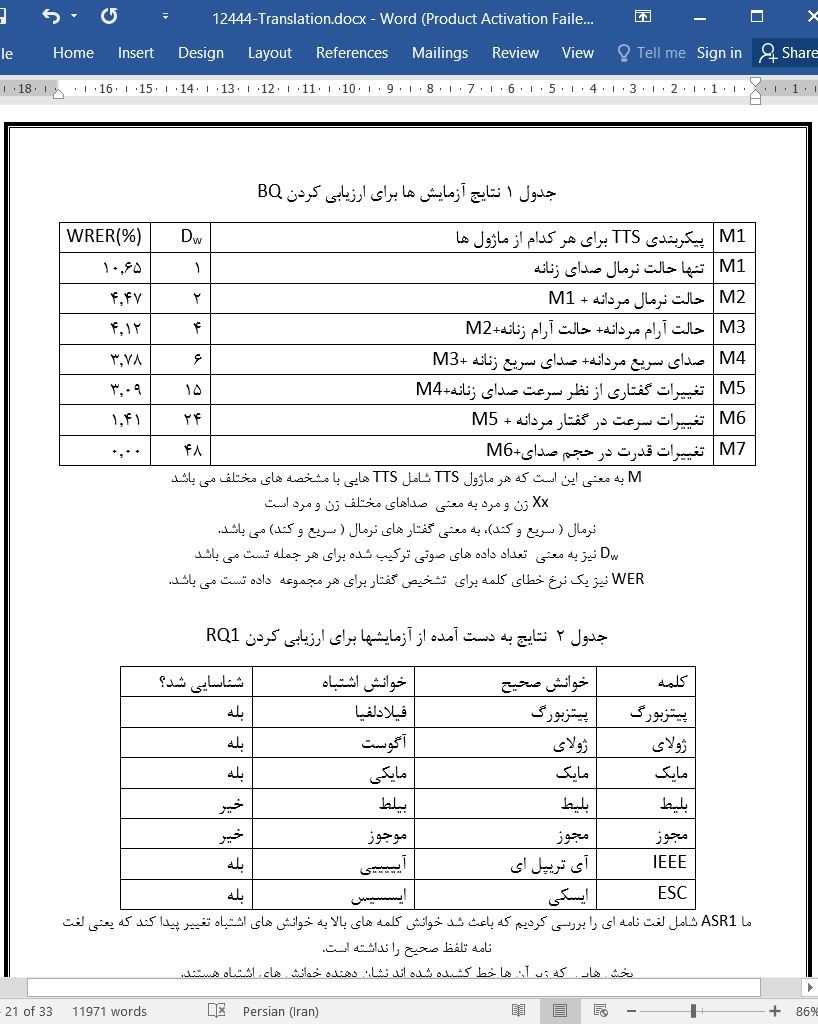
.svg)
.svg)

.svg)

ترجمه مقاله آزمایش خودکار قابلیت تشخیص پایه برای سیستم تشخیص گفتار - نشریه IEEE

عنوان فارسی
آزمایش خودکار قابلیت تشخیص پایه برای سیستم های تشخیص گفتار
عنوان انگلیسی
Automated Testing of Basic Recognition Capability for Speech Recognition Systems
صفحات مقاله فارسی
33
صفحات مقاله انگلیسی
12
سال انتشار
2019
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
آی تریپل ای - IEEE
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
کنفرانس
شناسه ISSN مجله
2159-4848
کد محصول
12444
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر - هوش مصنوعی - مهندسی الگوریتم ها و محاسبات - مهندسی نرم افزار
کلمات کلیدی
هوش مصنوعی - مهندسی الگوریتم ها و محاسبات - مهندسی نرم افزار
کلمات کلیدی انگلیسی
سیستم تشخیص گفتار - تست های خودکار - مدل سازی تست سیستم ASR
doi یا شناسه دیجیتال
https://doi.org/10.1109/ICST.2019.00012
۰.۰
(هنوز امتیازی ثبت نشده است)