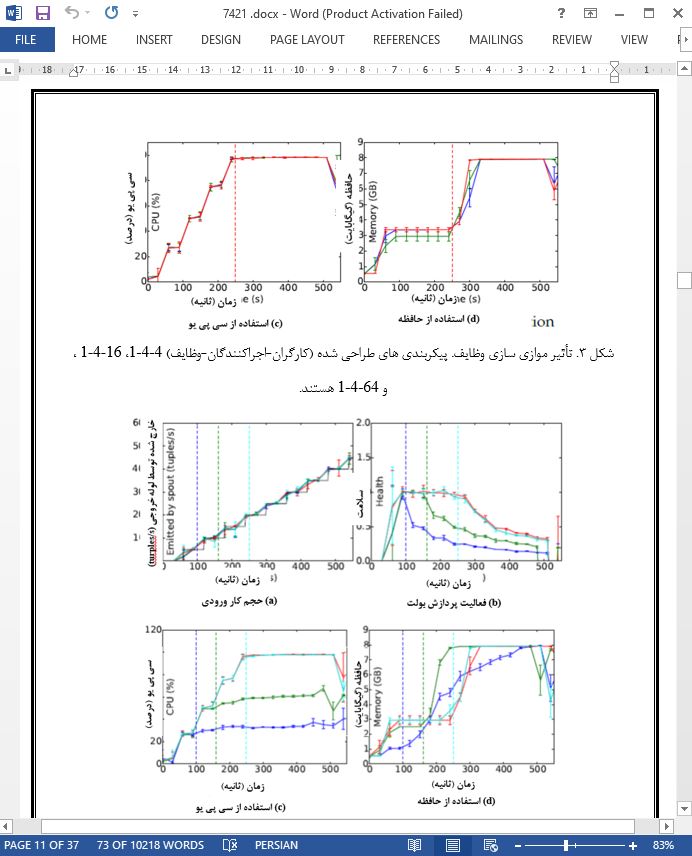
.svg)
.svg)

.svg)

ترجمه مقاله قابلیت ارتجاعی چند سطحی برای پردازش جریان داده ها - نشریه IEEE

عنوان فارسی
قابلیت ارتجاعی چند سطحی برای پردازش جریان داده ها
عنوان انگلیسی
Multi-Level Elasticity for Data Stream Processing
صفحات مقاله فارسی
37
صفحات مقاله انگلیسی
12
سال انتشار
2019
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
آی تریپل ای - IEEE
فرمت مقاله انگلیسی
PDF
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
4.154 در سال 2019
شاخص H_index مجله
130 در سال 2020
شاخص SJR مجله
0.929 در سال 2019
شناسه ISSN مجله
1045-9219
شاخص Q یا Quartile (چارک)
Q1 در سال 2019
کد محصول
7421
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
درج نشده است ☓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر، رایانش ابری
مجله
نتایج بدست آمده در حوزه سیستم های موازی و توزیع شده - Transactions on Parallel and Distributed Systems
دانشگاه
دانشگاه گرنوبل آلپ، گرنوبل، فرانسه
کلمات کلیدی
پردازش جریان، قابلیت ارتجاعی چند سطحی، آپاچی استورم
کلمات کلیدی انگلیسی
stream processing - multi-level elasticity - Apache Storm
doi یا شناسه دیجیتال
https://doi.org/10.1109/TPDS.2019.2907950
۰.۰
(هنوز امتیازی ثبت نشده است)