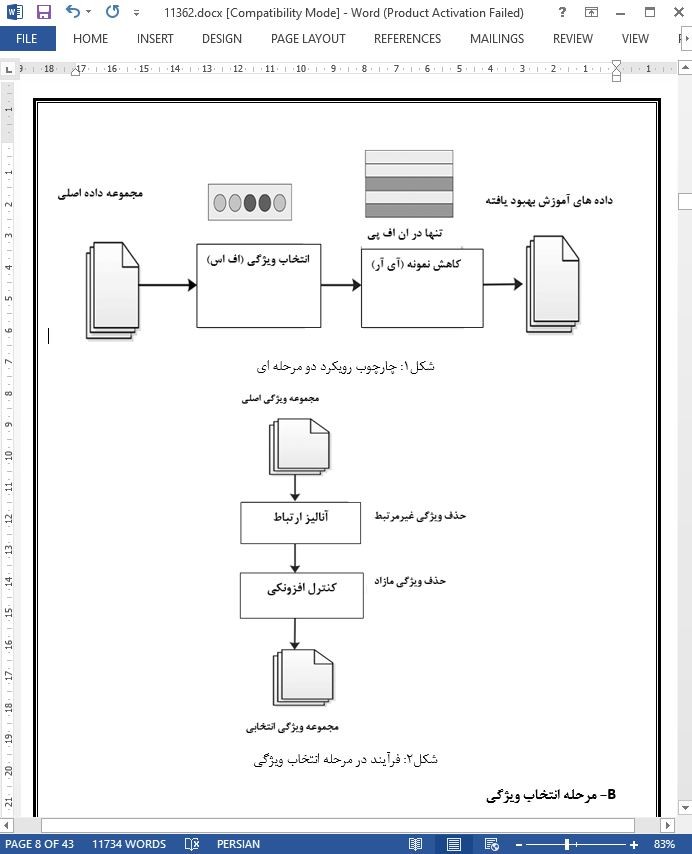
.svg)
.svg)

.svg)

ترجمه مقاله مطالعات تجربی یک رویکرد پیش پردازش داده دو مرحله ای برای پیش بینی خطای نرم افزار - نشریه IEEE

عنوان فارسی
مطالعات تجربی یک رویکرد پیش پردازش داده دو مرحله ای برای پیش بینی خطای نرم افزار
عنوان انگلیسی
Empirical Studies of a Two-Stage Data Preprocessing Approach for Software Fault Prediction
صفحات مقاله فارسی
43
صفحات مقاله انگلیسی
16
سال انتشار
2015
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
آی تریپل ای - IEEE
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
4.094 در سال 2019
شاخص H_index مجله
95 در سال 2020
شاخص SJR مجله
1.099 در سال 2019
شناسه ISSN مجله
0018-9529
شاخص Q یا Quartile (چارک)
Q1 در سال 2019
کد محصول
11362
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر، طراحی و تولید نرم افزار، مهندسی نرم افزار
دانشگاه
آزمایشگاه فناوری نرم افزار جدید، دانشگاه نانجینگ، چین
کلمات کلیدی
پیش بینی خطای نرم افزار، پیش گردازش داده، انتخاب ویژگی، کاهش نمونه، کنترل افزونگی، رتبه بندی ویژگی، مدل طبقه بندی
کلمات کلیدی انگلیسی
Software fault prediction - data preprocessing - feature selection - instance reduction - redundancy control - feature ranking - classification model
doi یا شناسه دیجیتال
https://doi.org/10.1109/TR.2015.2461676
۰.۰
(هنوز امتیازی ثبت نشده است)