

.svg)
.svg)

.svg)

ترجمه مقاله ردیاب های نفوذ مبتنی بر داده کاوی




عنوان فارسی
ردیاب های نفوذ مبتنی بر داده کاوی
عنوان انگلیسی
Data mining-based intrusion detectors
صفحات مقاله فارسی
25
صفحات مقاله انگلیسی
8
سال انتشار
2009
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
سایز ترجمه مقاله
14
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت مقاله انگلیسی
PDF
فونت ترجمه مقاله
بی نازنین
نشریه
الزویر - Elsevier
نوع ارائه مقاله
ژورنال
نوع مقاله
ISI
نوع نگارش
مقالات پژوهشی (تحقیقاتی)
ایمپکت فاکتور(IF) مجله
10.352 در سال 2022
پایگاه
اسکوپوس
شاخص H_index مجله
249 در سال 2023
شاخص Q یا Quartile (چارک)
Q1 در سال 2022
شاخص SJR مجله
1.873 در سال 2022
شناسه ISSN مجله
0957-4174
کد محصول
12610
بیس
نیست ☓
پرسشنامه
ندارد ☓
رفرنس در ترجمه
در داخل متن و انتهای مقاله درج شده است
ضمیمه
ندارد ☓
فرضیه
ندارد ☓
متغیر
ندارد ☓
مدل مفهومی
ندارد ☓
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه نشده است ☓
وضعیت ترجمه منابع داخل متن
ترجمه شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
doi یا شناسه دیجیتال
https://doi.org/10.1016/j.eswa.2008.06.138
رشته و گرایش های مرتبط با این مقاله
مهندسی فناوری اطلاعات - مهندسی صنایع - مهندسی کامپیوتر - داده کاوی - مهندسی الگوریتم ها و محاسبات - امنیت اطلاعات - اینترنت و شبکه های گسترده - رایانش ابری - علوم داده - مدیریت سیستم های اطلاعاتی
کلمات کلیدی
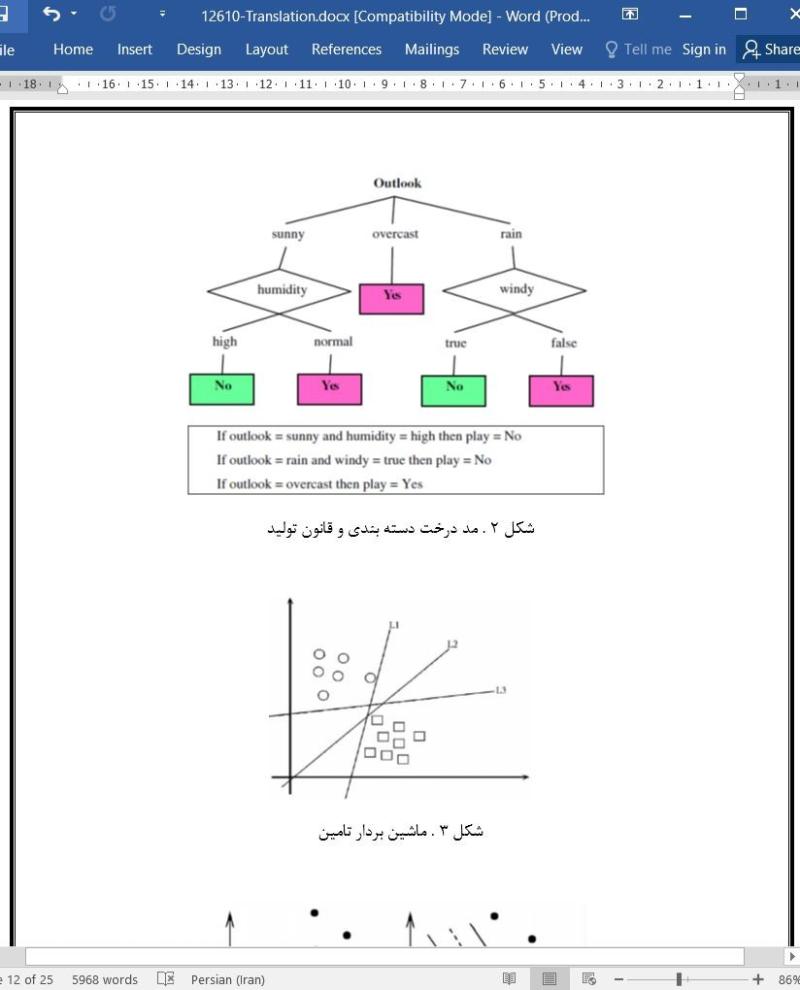
درخت دسته بندی - ماشین بردار تامین - حمله اینترنتی - سیستم تشخیص نفوذ (IDS)
کلمات کلیدی انگلیسی
Classification tree - Support vector machine - Internet attack - Intrusion detection system (IDS)
مجله
Expert Systems with Applications
۰.۰
(هنوز امتیازی ثبت نشده است)


