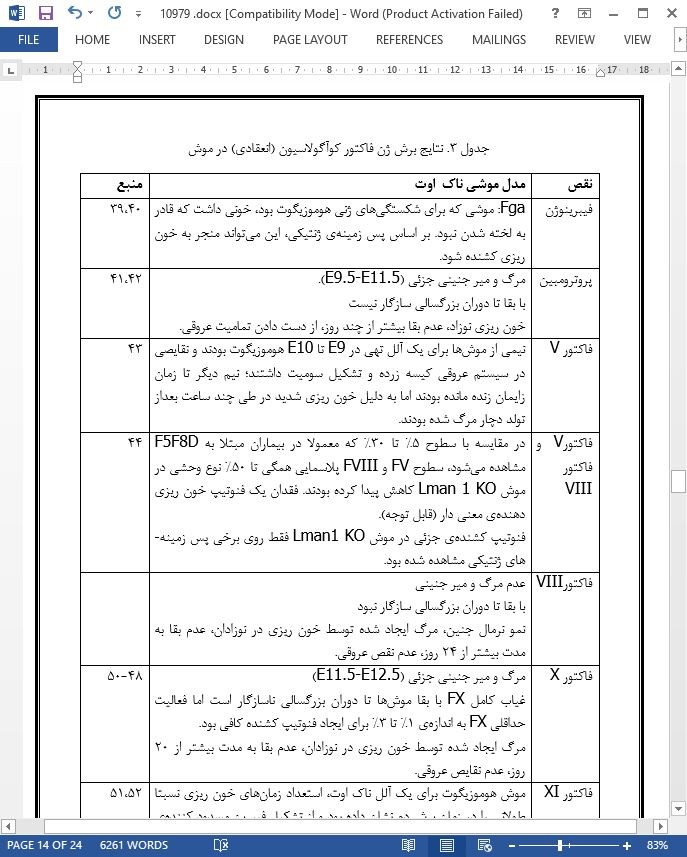
.svg)
.svg)

.svg)

ترجمه مقاله آنالیز توالی ژنتیکی بیماری های خون ریزی دهنده ارثی

عنوان فارسی
آنالیز توالی ژنتیکی بیماری های خون ریزی دهنده ارثی
عنوان انگلیسی
Genetic sequence analysis of inherited bleeding diseases
صفحات مقاله فارسی
23
صفحات مقاله انگلیسی
10
سال انتشار
2013
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
Ashpublications
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
مقالات مروری
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
10.565 در سال 2019
شاخص H_index مجله
448 در سال 2020
شاخص SJR مجله
5.416 در سال 2019
شناسه ISSN مجله
0006-4971
شاخص Q یا Quartile (چارک)
Q1 در سال 2019
کد محصول
10979
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
پزشکی و زیست شناسی، ژنتیک پزشکی، هماتولوژی، ژنتیک
مجله
خون - BLOOD
دانشگاه
گروه پاتوفیزیولوژی و پیوند، دانشگاه میلان، بنیاد لوئیجی ویلا، میلان، ایتالیا
doi یا شناسه دیجیتال
https://doi.org/10.1182/blood-2013-05-505511
۰.۰
(هنوز امتیازی ثبت نشده است)