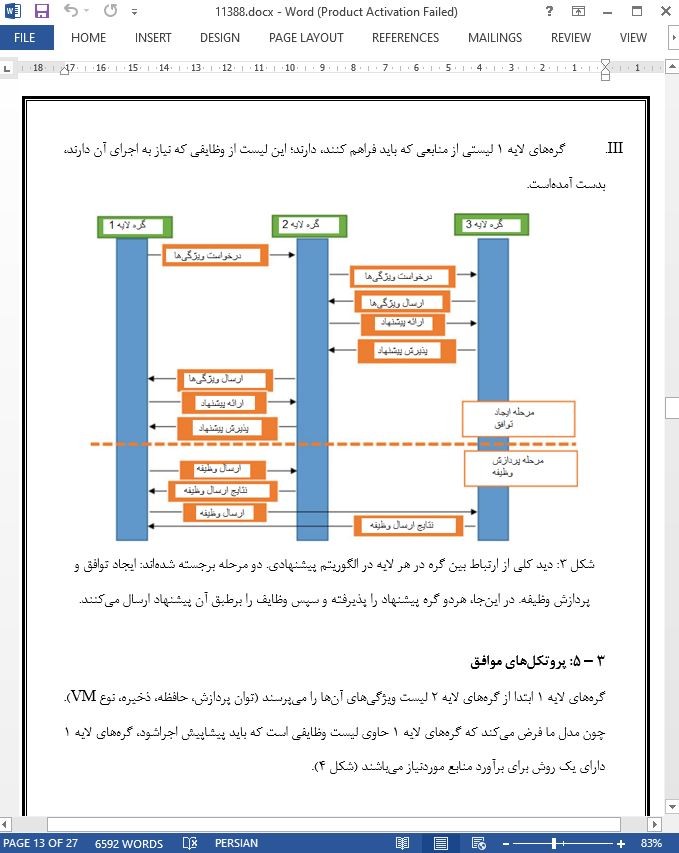
.svg)
.svg)

.svg)

ترجمه مقاله تخصیص منابع تطبیقی در پروتکل های موافق مبتنی بر رایانش ابری - نشریه اشپرینگر

عنوان فارسی
تخصیص منابع تطبیقی در پروتکل های موافق مبتنی بر رایانش ابری
عنوان انگلیسی
Adaptive Resource Allocation in Cloud Computing Based on Agreement Protocols
صفحات مقاله فارسی
27
صفحات مقاله انگلیسی
21
سال انتشار
2015
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
اشپرینگر - Springer
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
فصل کتاب (Book chapter)
نوع ارائه مقاله
ژورنال
شناسه ISSN مجله
2197-6503
کد محصول
11388
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته های مرتبط با این مقاله
مهندسی کامپیوتر و فناوری اطلاعات
گرایش های مرتبط با این مقاله
رایانش ابری، اینترنت و شبکه های گسترده
مجله
عوامل هوشمند در محاسبات داده های فشرده - Intelligent Agents in Data-intensive Computing
دانشگاه
دانشکده کنترل خودکار و کامپیوترها، گروه علوم کامپیوتر، دانشگاه Politehnica بخارست، رومانی
doi یا شناسه دیجیتال
https://doi.org/10.1007/978-3-319-23742-8_9
۰.۰
(هنوز امتیازی ثبت نشده است)