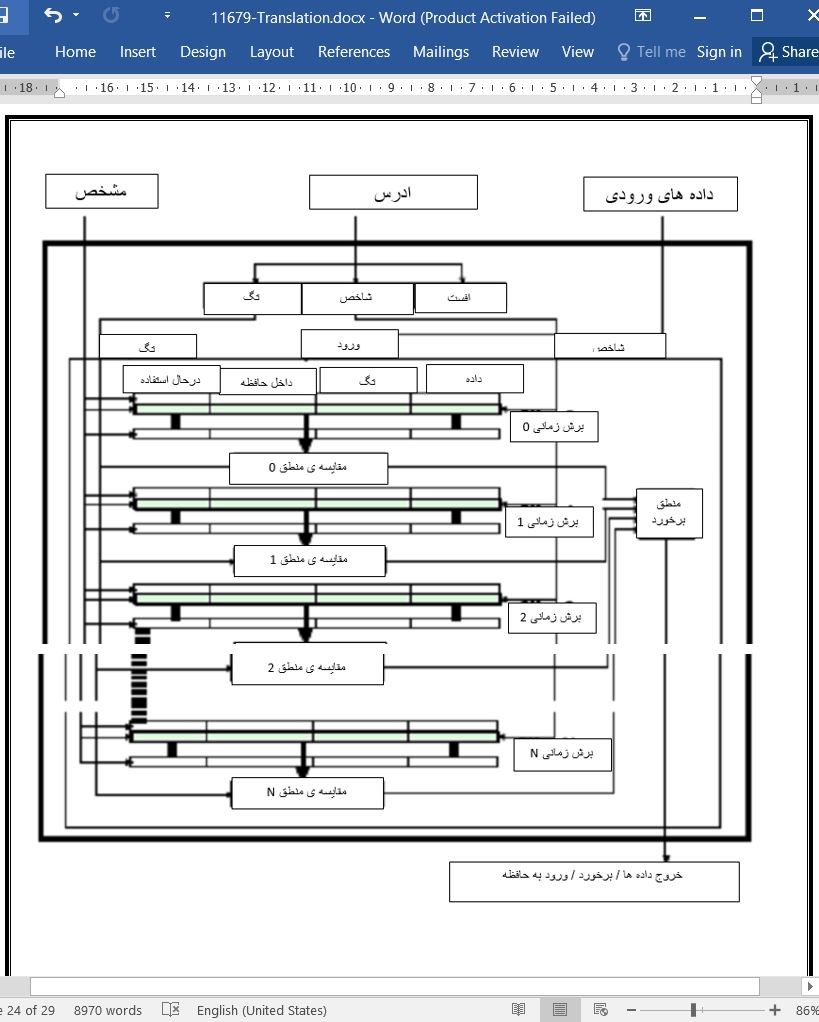
.svg)
.svg)

.svg)

ترجمه مقاله پشتیبانی از دستیابی به حافظه همروند در معماری پردازشگرهای TCF - نشریه الزویر
عنوان فارسی
پشتیبانی از دستیابی به حافظه همروند در معماری پردازشگرهای TCF
عنوان انگلیسی
Supporting concurrent memory access in TCF processor architectures
صفحات مقاله فارسی
29
صفحات مقاله انگلیسی
20
سال انتشار
2018
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
الزویر - Elsevier
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
مقالات پژوهشی (تحقیقاتی)
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
2.338 در سال 2020
شاخص H_index مجله
38 در سال 2021
شاخص SJR مجله
0.323 در سال 2020
شناسه ISSN مجله
0141-9331
شاخص Q یا Quartile (چارک)
Q3 در سال 2020
کد محصول
11679
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر، مهندسی الگوریتم ها و محاسبات و معماری سیستم های کامپیوتری
مجله
ریزپردازنده ها و میکروسیستم ها - Microprocessors and Microsystems
دانشگاه
محاسبات و ارتباطات کارآمد، فنلاند
کلمات کلیدی
محاسبات موازی، معماری پردازشگر، مدل برنامه نویسی، TCF، دستیابی به حافظه ی همروند
کلمات کلیدی انگلیسی
Parallel computing - Processor architecture - Programming model - TCF - Concurrent memory access
doi یا شناسه دیجیتال
https://doi.org/10.1016/j.micpro.2018.09.013
۰.۰
(هنوز امتیازی ثبت نشده است)