
ترجمه مقاله نقش ضروری ارتباطات 6G با چشم انداز صنعت 4.0
- مبلغ: ۸۶,۰۰۰ تومان
ترجمه مقاله پایداری توسعه شهری، تعدیل ساختار صنعتی و کارایی کاربری زمین
- مبلغ: ۹۱,۰۰۰ تومان


Abstract
With the fast development of information technology, the power data is growing at an exponentially speed. In the face of multi-dimensional and complicated power network data, the performance of the traditional clustering algorithms are not satisfied. How to effectively cope with the power network data is becoming a hot topic. This paper proposes a parallel implement of K-means clustering algorithm based on Hadoop distributed file system and Mapreduce distributed computing framework to deal this problem. The experimental results show that the performance of our proposed algorithm significantly outperforms the traditional clustering algorithm and the parallel clustering algorithm can significantly reduce the time complexity and can be applied in analyzing and mining of the power network data.
1 Introduction
Clustering [5] is one of the most hot issues in data mining research. It is the process of partitioning data objects into subsets. Each subset is a cluster [11], so that the objects in the cluster are similar to each other, but are not similar to the objects in other clusters. A set of clusters generated by the cluster analysis is called a cluster. With the continuous development of the electric power industry and the popularization of database technology, in the electric power industry, a large amount of data [6, 9] is accumulated in different forms. Then, how to store and utilize these data effectively and how to dig out valuable information from the massive data become problems to be solved
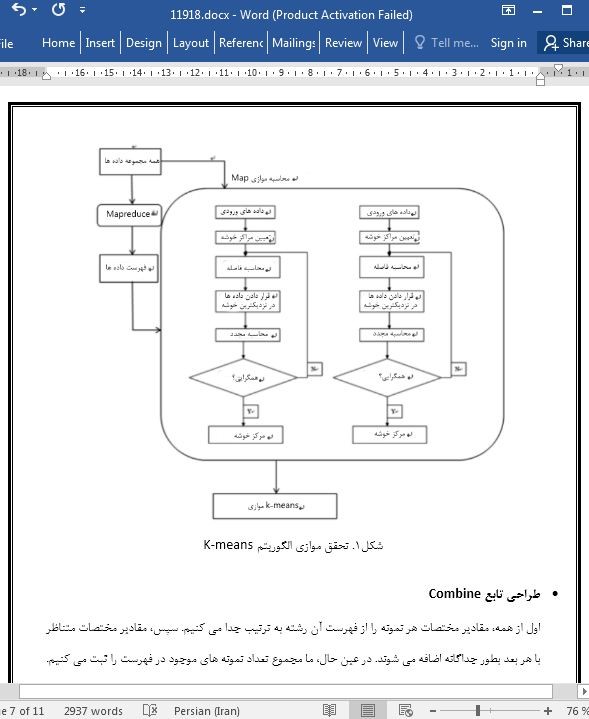
با توسعه سریع فن آوری اطلاعات، داده های نیرو نیز با سرعت قابل توجهی در حال رشد است. در مواجهه با داده های چند بعدی و پیچیدۀ شبکه نیرو، عملکرد الگوریتم های خوشه بندی سنتی رضایت بخش نیست. نحوه مؤثر مقابله با مسائل داده های شبکه نیرو به عنوان داغی تبدیل شده است. این مقاله اجرای موازی الگوریتم خوشه بندی K-means مبتنی بر سیستم فایل توزیع شده Hadoop و چارچوب محاسبات توزیعی Mapreduce را برای پرداختن به این مسئله پیشنهاد می دهد. نتایج تجربی نشان می دهد که عملکرد الگوریتم پیشنهادی ما به طور قابل توجهی از الگوریتم خوشه بندی سنتی بهتر است و الگوریتم خوشه بندی موازی می تواند پیچیدگی زمانی اجرای الگوریتم را تا حد زیادی کاهش دهد و می تواند در تجزیه و تحلیل و استخراج داده های شبکه نیرو استفاده شود.
1. مقدمه
خوشه بندی (5) یکی از داغترین موضوعات در تحقیقات داده کاوی است. آن فرایندی است که در آن شیئ داده ها در زیرمجموعه هایی تقسیم بندی می شوند. هر زیر مجموعه یک خوشه است (11)، به طوری که اشیاء موجود در خوشه شبیه به یکدیگرند، اما به اشیاء موجود در خوشه های دیگر شباهتی ندارند. مجموعه ای از خوشه های ایجاد شده توسط تجزیه و تحلیل خوشه ها، یک خوشه نامیده می شود. با توسعه مستمر صنعت برق و تعمیم فن آوری پایگاه داده در صنعت برق، مقدار زیادی از داده ها (9،6) به شکلهای مختلف گردآوری می شوند. بنابراین، نحوه موثر ذخیره سازی و استفاده بهینه از این داده ها و استخراج اطلاعات ارزشمند از داده های حجیم، مسائلی هستند که باید حل شوند.

