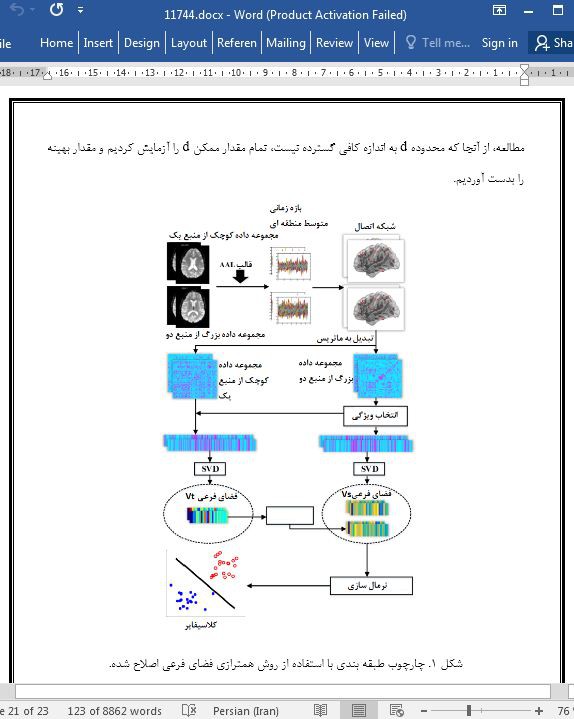
.svg)
.svg)

.svg)

ترجمه مقاله تشخیص بیماری آلزایمر در مجموعه داده های کوچک - نشریه IEEE

عنوان فارسی
تشخیص بیماری آلزایمر در مجموعه داده های کوچک: چشم انداز انتقال دانش
عنوان انگلیسی
Detecting Alzheimer’s Disease on Small Dataset: A Knowledge Transfer Perspective
صفحات مقاله فارسی
23
صفحات مقاله انگلیسی
9
سال انتشار
2018
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
آی تریپل ای - IEEE
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع ارائه مقاله
ژورنال
پایگاه
اسکوپوس
ایمپکت فاکتور(IF) مجله
6.977 در سال 2020
شاخص H_index مجله
125 در سال 2021
شاخص SJR مجله
1.293 در سال 2020
شناسه ISSN مجله
2168-2194
شاخص Q یا Quartile (چارک)
Q1 در سال 2020
کد محصول
11744
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه نشده است ☓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
وضعیت فرمولها و محاسبات در فایل ترجمه
به صورت عکس، درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
فرضیه
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
پزشکی و مهندسی کامپیوتر و بیوانفورماتیک پزشکی، هوش مصنوعی
دانشگاه
دانشکده اتوماسیون، پردازش تصویر و کنترل هوشمند آزمایشگاه وزارت آموزش چین، دانشگاه علم و صنعت Huazhong، ووهان، چین
کلمات کلیدی
تشخیص به کمک کامپیوتر، مجموعه داده کوچک، سازگاری دامنه، بیماری آلزایمر، rs-fMRI، یادگیری ماشین
کلمات کلیدی انگلیسی
Computer-aided diagnosis - Small dataset - Domain adaptation - Alzheimer’s disease - rs-fMRI - Machine learning
doi یا شناسه دیجیتال
https://doi.org/10.1109/JBHI.2018.2839771
۰.۰
(هنوز امتیازی ثبت نشده است)