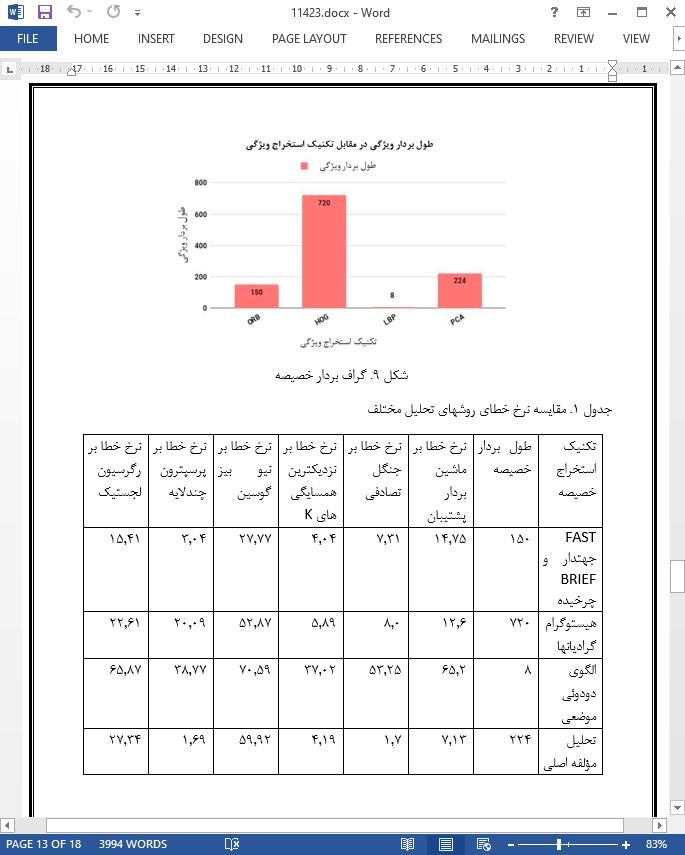
.svg)
.svg)

.svg)

ترجمه مقاله شناسایی حرکت دست ها با استفاده از تکنیک های پردازش تصویر و استخراج خصیصه - نشریه الزویر
عنوان فارسی
شناسایی حرکت دست ها با استفاده از تکنیک های پردازش تصویر و استخراج خصیصه
عنوان انگلیسی
Hand Gesture Recognition using Image Processing and Feature Extraction Techniques
صفحات مقاله فارسی
18
صفحات مقاله انگلیسی
10
سال انتشار
2020
رفرنس
دارای رفرنس در داخل متن و انتهای مقاله
نشریه
الزویر - Elsevier
فرمت مقاله انگلیسی
pdf و ورد تایپ شده با قابلیت ویرایش
فرمت ترجمه مقاله
pdf و ورد تایپ شده با قابلیت ویرایش
فونت ترجمه مقاله
بی نازنین
سایز ترجمه مقاله
14
نوع مقاله
ISI
نوع نگارش
مقالات پژوهشی (تحقیقاتی)
نوع ارائه مقاله
ژورنال
ایمپکت فاکتور(IF) مجله
1.636 در سال 2019
شاخص H_index مجله
59 در سال 2020
شاخص SJR مجله
0.342 در سال 2019
شناسه ISSN مجله
1877-0509
کد محصول
11423
وضعیت ترجمه عناوین تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه متون داخل تصاویر و جداول
ترجمه شده است ✓
وضعیت ترجمه منابع داخل متن
به صورت عدد درج شده است ✓
ضمیمه
ندارد ☓
بیس
نیست ☓
مدل مفهومی
ندارد ☓
پرسشنامه
ندارد ☓
متغیر
ندارد ☓
رفرنس در ترجمه
در انتهای مقاله درج شده است
رشته و گرایش های مرتبط با این مقاله
مهندسی کامپیوتر، هوش مصنوعی، مهندسی الگوریتم ها و محاسبات، مهندسی نرم افزار
مجله
پروسدیا علوم کامپیوتر - Procedia Computer Science
دانشگاه
موسسه فناوری Maharaja Agrasen ، دانشگاه گورو گوبیند سینگ ایندراپراستا، دهلی، هند
کلمات کلیدی
شناسایی حرکت دستها، یادگیری ماشینی، پردازش تصویر، زبان اشاره آمریکایی، طبقه بندی چند کلاسی
کلمات کلیدی انگلیسی
Hand Gesture Recognition - Machine Learning - Image Processing - American Sign Language - Multi-Class Classification
doi یا شناسه دیجیتال
https://doi.org/10.1016/j.procs.2020.06.022
۰.۰
(هنوز امتیازی ثبت نشده است)